Carlos, and please don't take it the wrong way, but I think you are confusing yourself more than needed by jumping into Japanese codepages before fully exploring the common issues present in the - relatively simpler case of - western languages.
carlos wrote:I'm convinced that cmd internally stores the text using 2 bytes for each character, no more than it, because the environment block use widechar (wchar_t) that are 2 bytes
That's not a matter of opinion

and, sorry, but fact is that you are mistaken. It is true that all Windows (not just cmd) use 16b wchar_t's for storing strings - but some Unicode codepoints require 2 wchar_t's. Just lookup the UTF16 specs, surrogates, extended planes etc. What you're thinking at (one 16b value per character) sounds more like UCS-2 which I believe was used in NT 3.x once upon a time, but then expanded to UTF16 since at least Win2K.
carlos wrote:In input it translate a byte secuence treating it as multibyte (1 or 2 bytes (no more than it)) using the current codepage to 2 bytes character internally representation.
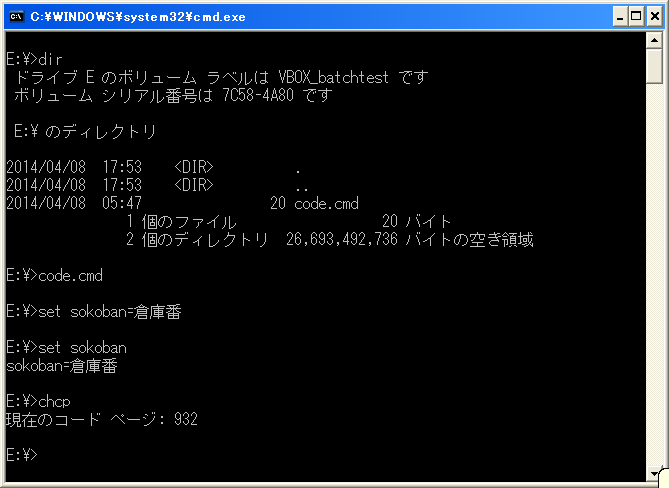
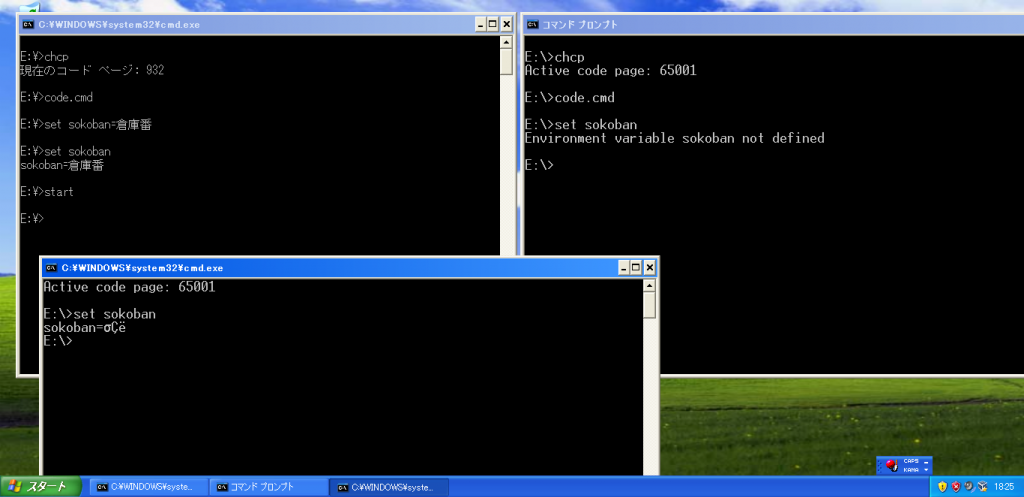
There is no translation on interactive input (except in really rare cases when you copy/paste from some ancient app that only puts 8-bit text onto the clipboard). For a quick test (no Japanese required) paste this "echo ‹αß©∂€›" at a cmd prompt in any of the common codepages - 437, 850, 1252 - and then execute it. You'll get the text pasted correctly, and the output of "echo" will be correct - using any of those codepages - still neither of those codepages contains all characters in the string that was pasted. This should make it obvious that what's pasted is the fully Unicode string, without any conversion to the active codepage. (
Note: as always when codepages and Unicode are involved, you should be using a Unicode/TT - not raster - font in the console. Besides aesthetics, using a raster font actually changes the automatic codepage conversions done by the console, for output in particular - see the MSDN SetConsoleOutputCP docs "
if the current font is a raster font, SetConsoleOutputCP does not affect how extended characters are displayed".)
carlos wrote:Then /A output option is multibyte, not single byte.
The /A output is single or multi-byte depending on the codepage being SBCS (single byte) or MBCS (multi byte). All "western" codepages (437, 850, 1252 etc) are single byte.
carlos wrote:Some real example that show that cmd holding a unicode character that use more than 2 bytes for represent it? I keep that cmd cannot do it.
So far, cmd doesn't display surrogates correctly, that much is true - but that's just a shortcoming of particular cmd versions. It doesn't change what UTF16 means and how it's supported by Windows itself. To see an example of a 2-wchar_t (4-byte) Unicode codepoint:
- open
http://www.alanwood.net/unicode/mathematical_alphanumeric_symbols.html;
- depending on your browser and settings, the leftmost char on the first line under "Character" should display as either a funky "A" or maybe a <box> placeholder;
- regardless of how the browser displays it, select that character and copy it to the clipboard;
- now run Wordpad and paste it;
- if you have the Cambria Math font installed, Ctrl-A and change the font to Cambria Math (if you don't have the font, see
http://en.wikipedia.org/wiki/Cambria_(typeface) for ways to get it - include free MS Office viewers etc);
- if using Cambria Math, Wordpad would show that same funky "A", otherwise some <box> placeholder;
- regardless of what's displayed, do a Save-As, select type "Unicode document", give it some name and save it.
At this point, you should have a 6-byte long file, with hex contents "FF FE 35 D8 00 DC". This is the 2-byte UTF16-LE BOM "FEFF" plus the 2-double-byte "D835 DC00" UTF16 encoding of U+1D400 - the selected Unicode character "MATHEMATICAL BOLD CAPITAL A". Note that the contents of the file is one single Unicode character, which takes 4 bytes to encode as UTF16-LE.
aGerman wrote:You have to clearly separate the unicode support of cmd.exe from the ability to display unicode characters in the console window.
That's good advice, indeed. To add to that, one must also separate between the Unicode support built in and provided by Windows itself vs. what/how programs choose to use that support - and both change from version to version. For an example, the XP Notepad doesn't display surrogates correctly, though XP itself offers the necessary support (which Wordpad takes advantage of). However, the Win7 Notepad does have the proper surrogates support.
Liviu